谷歌提示词工程 - 最佳实践

接上文谷歌提示词工程 - 模型原理和提示词技术,讨论提示词的最佳实践。

提供示例
正如上文提示词技术提到的单样本、少样本那样,在提示中提供样例十分重要。这样模型就能在示例的参考下输出更加准确的内容。
简约设计
基本原则是:若你自己都觉得困惑,模型很可能也会困惑。避免使用复杂语言,且不要提供无关信息。
尝试使用描述动作的动词。以下是一组示例:
行动、分析、归类、分类、对比、比较、创造、描述、定义、评估、提取、发现、生成、识别、列举、测量、组织、解析、挑选、预测、提供、排序、推荐、返回、检索、改写、选择、展示、整理、总结、翻译、撰写。
明确提出需求
详细说明期望输出。简短的指令可能无法充分引导大语言模型,或过于笼统。在提示中提供具体细节(通过系统或上下文提示)有助于模型聚焦相关内容,提高整体准确性。
优先使用指令而非约束
提示中使用的指令和约束用于引导大语言模型的输出。
尽可能使用正向指令:用“应该做什么”替代“禁止做什么”,这能避免混淆并提高输出准确性。
约束条件在特定场景仍具价值:当需要防止模型生成有害/偏见内容,或要求严格输出格式时。
作为最佳实践,应优先处理指令,明确说明您希望模型执行的操作,仅在出于安全性、清晰度或特定需求时使用约束条件。通过实验与迭代测试不同指令和约束的组合,以找到最适合您特定任务的方案,并予以记录。
控制最大令牌长度
要控制生成式大语言模型(LLM)的响应长度,您可以在配置中设置最大令牌限制,或在提示词中明确指定所需长度。例如:
"Explain quantum physics in a tweet length message."
在提示词中使用变量
为了实现提示词复用并增强动态性,可在提示词中使用变量,这些变量可根据不同输入进行替换。

尝试不同的输入格式与写作风格
不同模型、配置、提示格式、措辞和提交方式会产生不同结果。因此需对提示属性进行实验,如风格、措辞及提示类型(零样本、少样本、系统提示) 。
分类任务的小样本提示中,需混合不同类别
一般而言,小样本示例的顺序影响不大。但在执行分类任务时,务必在少量示例中混合可能的响应类别。这是因为固定顺序可能导致模型对示例顺序产生过拟合。通过混合响应类别,可确保模型学会识别各类别的关键特征,而非简单记忆示例顺序。这种方法能提升模型在未见数据上的鲁棒性和泛化性能。
经验法则建议从6个少��量示例开始,并由此测试准确度。
适应模型更新
紧跟模型更新,尝试新版模型调整提示词充分利用新特性。
尝试不同输出格式
除输入格式外,还可探索输出格式。对于数据提取、筛选、解析、排序、分级或分类等非创造性任务,建议采用JSON或XML等结构化格式返回结果。
JSON 修复
JSON 格式校验严格,可以使用 PyPI 的 json-repair 智能修复 JSON 格式。
使用 Schema
输入数据也可以使用 JSON 格式高效的组织数据。
与其他提示工程师协同实验
当每个人都遵循本章所述的最佳实践时,您将观察到不同提示方案间的性能差异。
思维链最佳实践
进行思维链提示时,必须将答案置于推理过程之后,因为推理过程的生成会改变模型预测最终答案时所获得的标记(token)。
使用思维链与自洽性方法时,需确保能从提示中分离出最终答案,使其独立于推理过程。
思维链提示的温度参数应设为0。
思维链提示基于贪婪解码机制,即语言模型根据概率最高中的下一个词。一般而言,当涉及推理得出最终答案时,通常存在唯一正确答案,因此温度参数应始终设置为0。
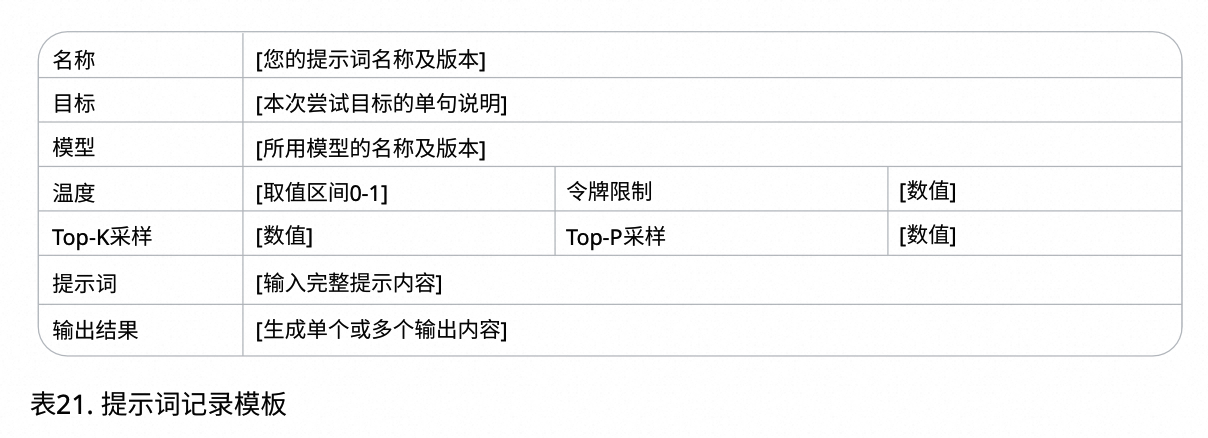
记录不同提示尝试方案
细记录每次提示尝试的完整细节,这样才能逐步总结出哪些方法有效,哪些无效。
提示工程是一个迭代过程。设计并测试不同提示方案,分析记录结果,根据模型表现优化提示词。持续实验直至获得理想输出。当更换模型或调整模型配置时,需重新用先前提示词进行实验验证。
欢迎关注我的公众号:前端生存指南,一起聊聊前端、AI 和生活。
