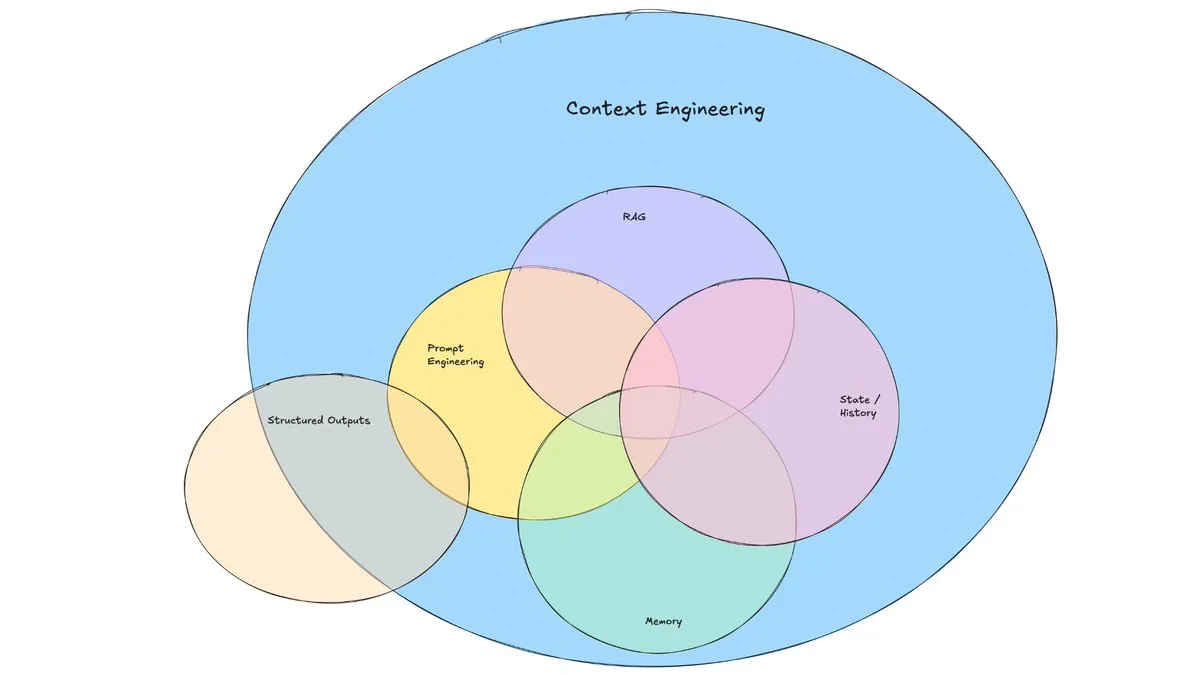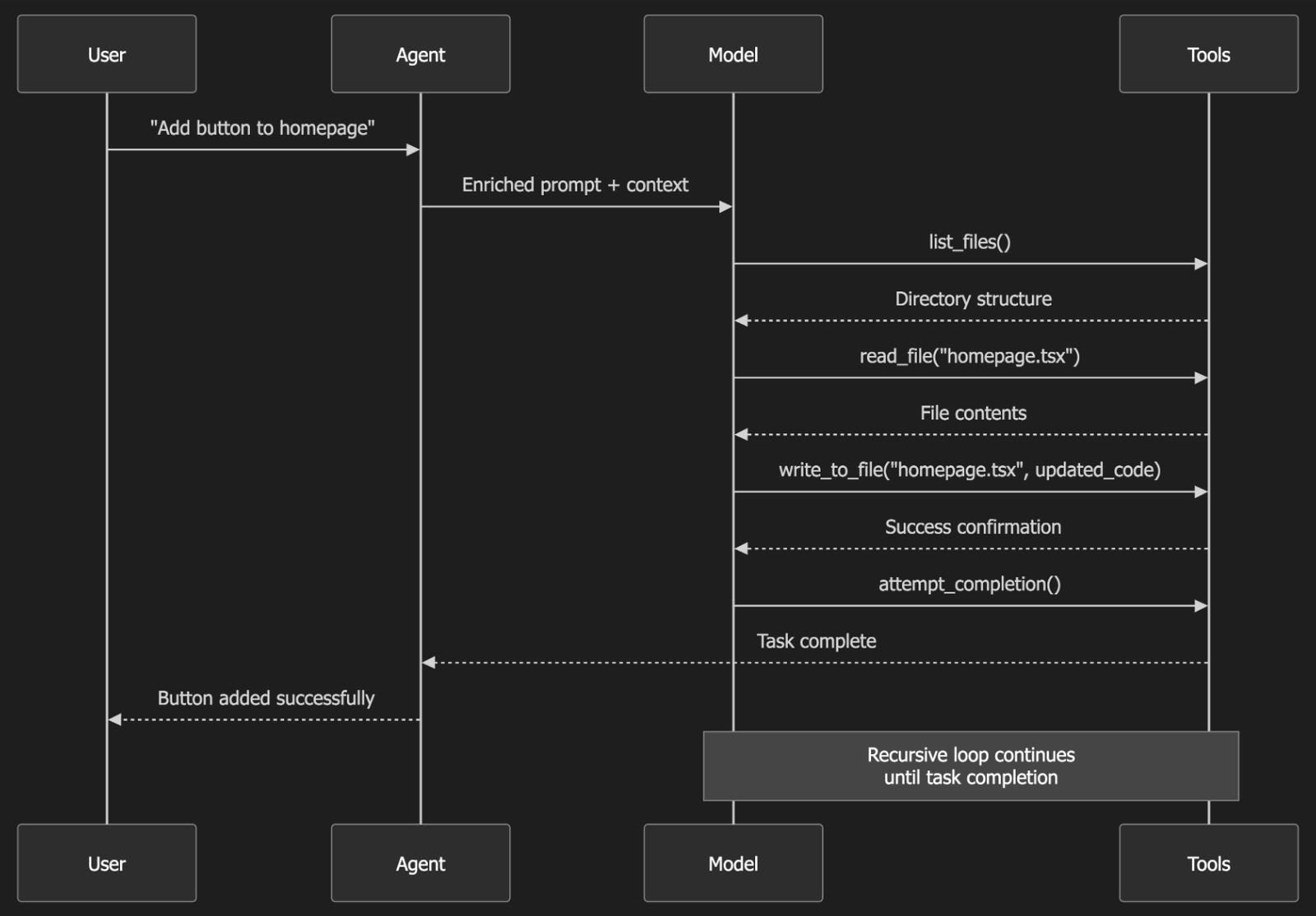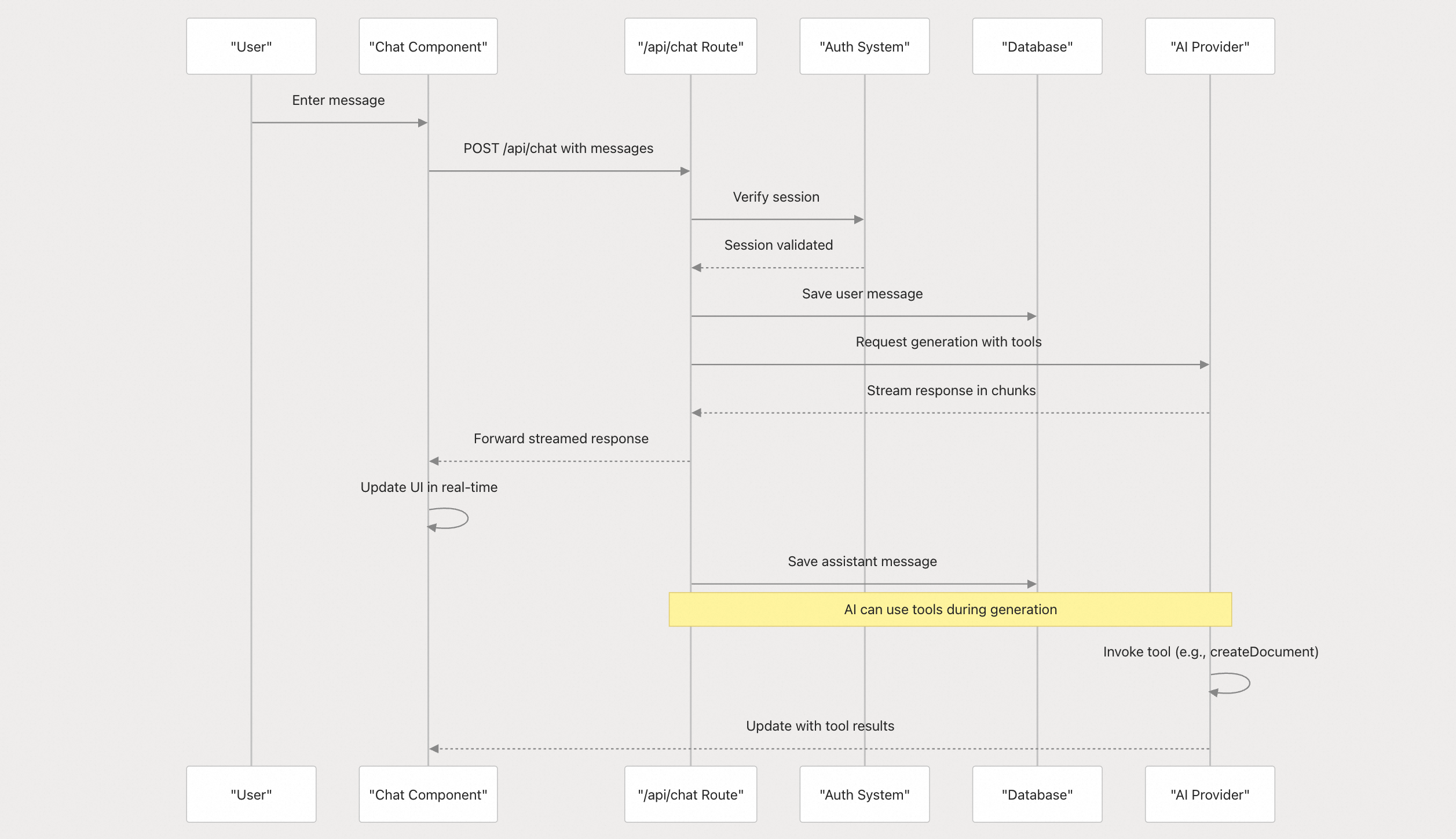
“Agent 就是如何拼出更好用的 Prompt”,虽然有点玩笑的意味,但也能说明一定的问题。本篇文章我们探讨下 Cline 里的 Prompt 设计。
System Prompt
众所周知,System Prompt 是 Agent 的核心资产😂,Github 上 system-prompts-and-models-of-ai-tools 这个仓库收集了各类 AI 应用的 System Prompt,已经有 56.6K 的 Star 了,可见一斑。
Cline 的 System Prompt 位于 src/core/prompts/system.ts,根据上下文信息、工具以及模型信息动态生成。
You are Cline, a highly skilled software engineer with extensive knowledge in many programming languages, frameworks, design patterns, and best practices.
You have access to a set of tools that are executed upon the user's approval. You can use one tool per message, and will receive the result of that tool use in the user's response. You use tools step-by-step to accomplish a given task, with each tool use informed by the result of the previous tool use.
我们自上而下的读一遍 System Prompt。
- 工具调用格式
首先告诉模型使用 XML 语法输出工具调用相关的内容。
<tool_name>
<parameter1_name>value1</parameter1_name>
<parameter2_name>value2</parameter2_name>
...
</tool_name>
- 工具列表
列举了 Cline 内置的工具,主要包括描述、参数以及使用 DEMO,比如 write_to_file:
## write_to_file
Description: Request to write content to a file at the specified path. If the file exists, it will be overwritten with the provided content. If the file doesn't exist, it will be created. This tool will automatically create any directories needed to write the file.
Parameters:
- path: (required) The path of the file to write to (relative to the current working directory ${cwd.toPosix()})
- content: (required) The content to write to the file. ALWAYS provide the COMPLETE intended content of the file, without any truncation or omissions. You MUST include ALL parts of the file, even if they haven't been modified.
Usage:
<write_to_file>
<path>File path here</path>
<content>
Your file content here
</content>
</write_to_file>
Cline 内置了十多个工具,覆盖了命令行、文件操作、浏览器、MCP 等,这些工具极大的丰富了模型的能力。
- 工具调用 Example
展示了多个工具调用的样例给模型参考:
# Tool Use Examples
## Example 1: Requesting to execute a command
<execute_command>
<command>npm run dev</command>
<requires_approval>false</requires_approval>
</execute_command>
- 工具使用指引
这里相当于手把手教模型逐步思考如何使用工具(类似于思维链(CoT)),简单翻译如下:
1)首先,模型需要评估已经掌握的信息,使用 <thinking> 标签包裹。
2)根据任务和提供的工具描述,选择最合适的工具。
3)如果需要执行多个操作,请一次只使用一个工具,每一步都必须以前一步的结果为依据。
4)使用指定的 XML 格式来构建你的工具调用。
5)每次使用工具后,用户将回复该工具的执行结果。这个结果会为你提供继续任务或做出进一步决策所需的信息。
6)每次使用工具后,一定要等待用户的确认后再继续。
以上的操作,可以确保模型按步骤拆解任务,确认每步的成功与否,根据用户的反馈实时进行调整,保证工具使用和最�终任务的正确性。
MCP Server
这部分我们在 Cline 源码浅析 - MCP 调用聊过,这里不再展开。
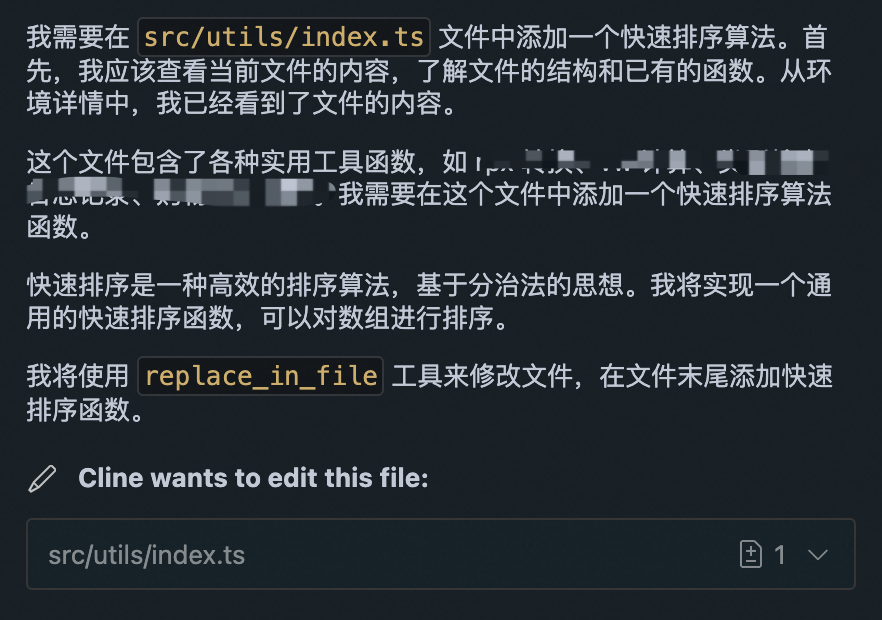
文件编辑 EDITING FILES
对于 Code Agent 文件编辑是非常重要的部分,这里再次强调了 write_to_file 和 replace_in_file 两个工具的使用:详细的使用时机以及重要提示。
再次以 workflow 的方式告诉模型使用文件编辑工具的最佳实践:
1. 在进行编辑之前,评估你更改的范围,并决定使用哪个工具。
2. 对于有针对性的修改,请使用 `replace_in_file` 工具,并精心编写 SEARCH/REPLACE 块。如果你需要进行多项更改,可以在一个 `replace_in_file` 调用中堆叠多个 SEARCH/REPLACE 块。
3. 对于大规模重构或初始文件创建,请依赖 `write_to_file` 工具。
4. 一旦文件通过 `write_to_file` 或 `replace_in_file` 被编辑,系统将向你提供修改后文件的最终状态。请将此更新后的内容作为后续所有 SEARCH/REPLACE 操作的参考点,因为它反映了任何自动格式化或用户手动应用的更改。
通过在 `write_to_file` 和 `replace_in_file` 之间做出深思熟虑的选择,你可以使文件编辑过程更加顺畅、安全和高效。
Act Mode 和 Plan Mode
Cline 提供了两种模式:Plan 和 Act。对于复杂任务,Cline 推荐从 Plan 模式开始,让模型先行规划策略,然后切换到 Act 模式,按照规划逐步实施,以提高代码输出质量。对话过程中,可以在两个模式中切换,就像人一样,写代码过程中,遇到问题,停下来思考。
System Prompt 里详细描述了两种模式的差异,重点描述了一下 Plan 模式的规则,比如使用 read_file search_files 等工具了解信息,特别推荐使用图表直观展示信息,并强调 Plan 模式下会使用 plan_mode_respond 工具回复信息。
功能 CAPABILITIES
这一大段相当于把上面的工具集进行了一次总结,告诉模�型有用哪些能力,可以使用哪些特定工具来完成特定的功能,比如命令行:
You can use the execute_command tool to run commands on the user's computer whenever you feel it can help accomplish the user's task. When you need to execute a CLI command, you must provide a clear explanation of what the command does. ......
规则 RULES
规则部分主要强调了什么可以做,什么不能做。比如不可以使用 ~ 或 $HOME 来表示用户的主目录,不可以使用 cd 命令,不能口语化,必须等待用户确认。这里使用了大量的** ** 加粗的标记提醒模型。
系统信息
获取系统信息,这些可以帮助命令行工具、文本读写工具的执行。
Operating System: ${osName()}
Default Shell: ${getShell()}
Home Directory: ${os.homedir().toPosix()}
Current Working Directory: ${cwd.toPosix()}
这里奠定了 Cline 处理问题的基调,我完整的贴在这里:
你通过迭代的方式完成给定的任务,将其分解为清晰的步骤,并有条不紊地逐一执行。
1. **分析用户的任务**,设定明确且可实现的目标以完成它。按逻辑顺序对这些目标进行优先级排序。
2. 依次处理这些目标,在必要时一次使用一个可用工具。每个目标应对应你解决问题过程中的一个具体步骤。在整个过程中,你会被告知已完成的工作和剩余的任务。
3. 请记住,你拥有广泛的工具能力,可以灵活、巧妙地运用这些工具来完成每一个目标。在调用任何工具之前,请在 `<thinking></thinking>` 标签中进行分析:
- 首先,分析 `environment_details` 中提供的文件结构,以获取上下文和洞察,从而有效地推进任务。
- 然后,思考哪个可用工具最相关,能够帮助你完成用户任务。
- 接着,逐个检查该工具所需的参数,并判断用户是否已直接提供或提供了足够的信息用于推断参数值。在决定能否推断某个参数值时,请仔细考虑所有上下文,看是否支持特定的取值。
- 如果所有必需的参数都已存在或可以合理推断,则关闭 `<thinking>` 标签并继续执行工具操作。
- **但如果有一个必需参数的值缺失**,**不要调用该工具**(即使填入占位符也不行),而是使用 `ask_followup_question` 工具向用户请求缺失的参数。如果未提供的是**可选参数**,则**不要主动询问**。
4. 完成用户的任务后,你必须使用 `attempt_completion` 工具将结果提交给用户。你也可以提供一条 CLI 命令来展示任务的结果;这对于 Web 开发任务尤其有用,例如你可以运行 `open index.html` 来展示你构建的网站。
5. 用户可能会提供反馈,你可以根据反馈进行改进并重新尝试。但**不要陷入无意义的来回对话中**,也就是说,**不要以问题或提供进一步帮助的提议结束你的回复**。
自定义 System Prompt
在 addUserInstructions 方法中,追加用户自定义的指令,这里包括了 Cline Rules。我们可以在项目根目录下新建 .clinerules/ 存放 Cline Rule,Cline 作为 System Prompt 最有效的补充,可以针对不同的项目做不同的定制。
甚至追加了 Cursor 或者 Windsurf 的 Rule。😂
if (localCursorRulesFileInstructions) {
customInstructions += localCursorRulesFileInstructions + "\n\n"
}
if (localCursorRulesDirInstructions) {
customInstructions += localCursorRulesDirInstructions + "\n\n"
}
if (localWindsurfRulesFileInstructions) {
customInstructions += localWindsurfRulesFileInstructions + "\n\n"
}
Claude4 支持
Cline 3.17.9 版本对 Claude4 做了特殊支持 src/core/prompts/model_prompts/claude4.ts 以及 src/core/prompts/model_prompts/claude4-experimental.ts。据官方博客描述,在使用新的 Claude4 模型时,会遇到一些编辑错误。
这次版本更新主要关注 Cline 与 Claude 4 之间的交互,尤其是在搜索和替换操作上。我们调整了分隔符方法,将 < 和 > 替换为 - 和 + ,这在我们的内部测试中显示出了积极的效果,减少了编辑失败,提高了代码修改的成功率。
这也给我们带来了一些提示:在模型切换时,需要及时的测试和调整 Prompt,以更好的适应更新更强大的模型。
Command 和 Workflow
除了 Cline Rules,Cline 还提供了其他方式来让用户定制 Prompt。
Slash Command
Cline 提供了 Slash Command 的概念,通过 / 触发。
不像 Cline Rule 会针对每个任务生效,Command 在实现特定类型任务的时候很有用。比如我们要反馈 Bug,就可以使用内置的 /reportBug 触发任务。而比如在执行其他任务,比如写代码时,不带上这个命令,也就不会发送相应的提示词给模型。
Command 相应的提示词位于 src/core/prompts/commands.ts,提示词组装过程中,会调用 src/core/slash-commands/index.ts 文件的 parseSlashCommands 方法,将 / 命令替换为指定的提示词。
Workflow
如果要自定义 Command,除了源码层面定制,Cline 也支持用户手动配置,Cline 称其为 Workflow,Workflow 允许用户自定义步骤来处理特定的任务。在 .clinerules 目录下新建 workflows 目录,目录下新建 markdown 文件,文件内容我处理特定任务的步骤。这时候聊天框中输入 /,就会发现命令列表多了我们定制的 /[workflow-name.md]。
这部分逻辑依然在 parseSlashCommands 方法内,Command 和 Workflow 都会处理成 / 命令。
可以参照 Cline 仓库的 .clinerules/workflows/pr-review.md 编写自己的 Workflow。
Mention @
@ 在 Cline 中是作为引用外部资源扩展上下文存在的。
比如你可以 @ 一个文件路径,那这个文件的内容就会作为 Prompt 带给大模型。格式如下:
<file_content path="path/to/file">
[Complete file content]
</file_content>
除了文件,还可以 @ 问题、命令行甚至是一个 url,不必输入大段文字即可提供给模型更丰富的上下文信息。
mention 相关处理位于 src/core/mentions/index.ts,处理了各种 @ 信息。实践中,我们可以扩展 @能力,比如 @我们内部的知识库来让 Cline 更好的了解团队内部知识。
Memery Bank
Memery Bank 是 Cline Agent 记忆系统的一个解决方案,[Cline Blog] 将 Memery Bank 比喻为笔记本,随着项目的更新持续的更新笔记,这样在开始新任务丢失历史记录和上下文的情况下,Cline 依旧可以通过笔记本里的内容了解项目全貌、技术架构以及当前进度等信息。
我们可以在 .clinerules 目录下新建 memory-bank.md,内容可以参照官方文档给出的示例。
这份示例要求模型以如下的文档关系整理笔记本:
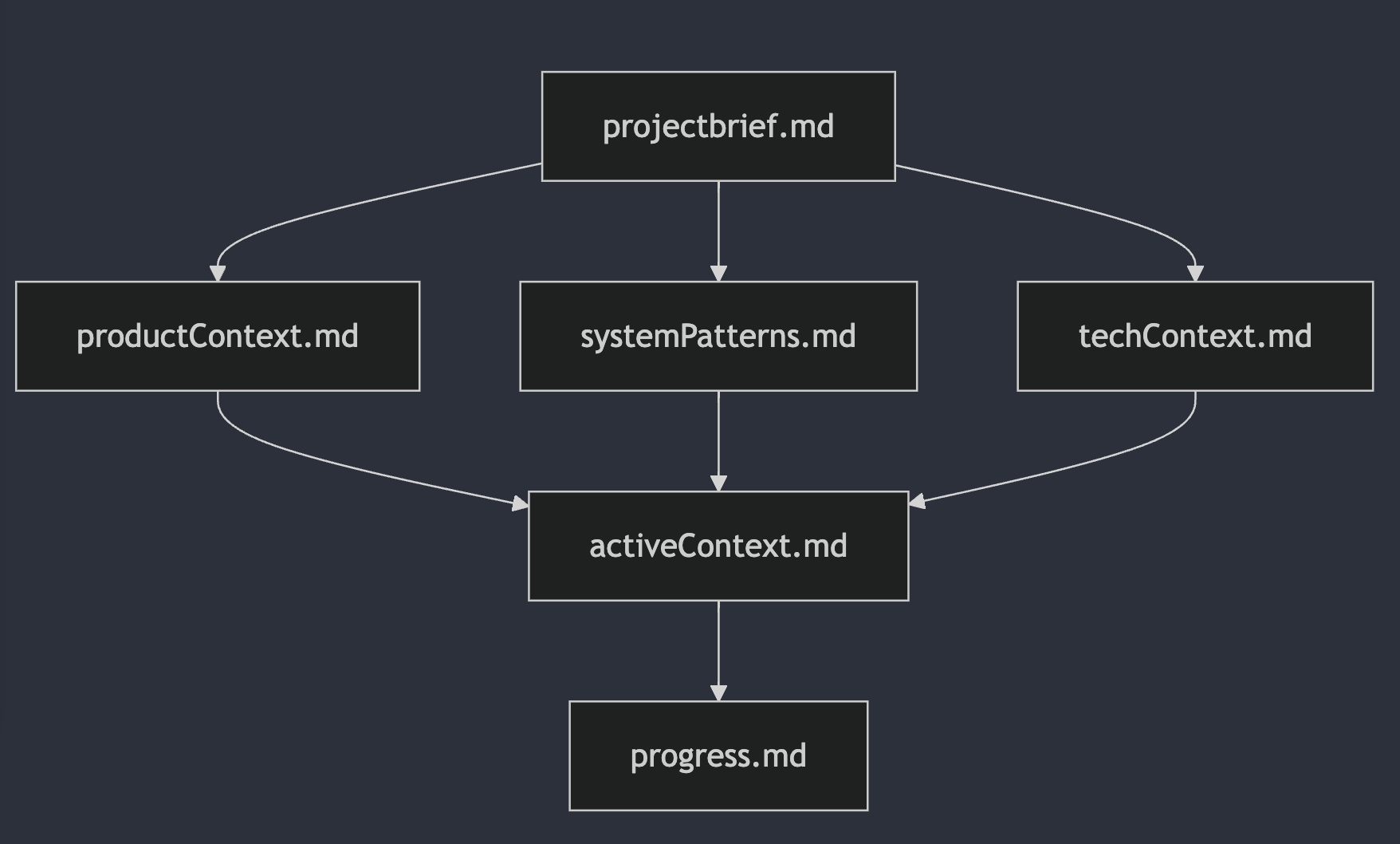
这六个文件分别作用为:
projectbrief.md: 项目简介,奠定一切的基础文档
productContext.md: 产品上下文,商业和用户视角
systemPatterns.md: 技术架构与决策
techContext.md: 开发环境和技术栈
activeContext.md: 当前开发状态
progress.md: 项目进度与跟踪
实际工作中,工作前需要确认 Memory Bank 文件,获取必要的上下文知识,如果项目有重大更新,则更新相关文档,以应对上下文丢失的情况。
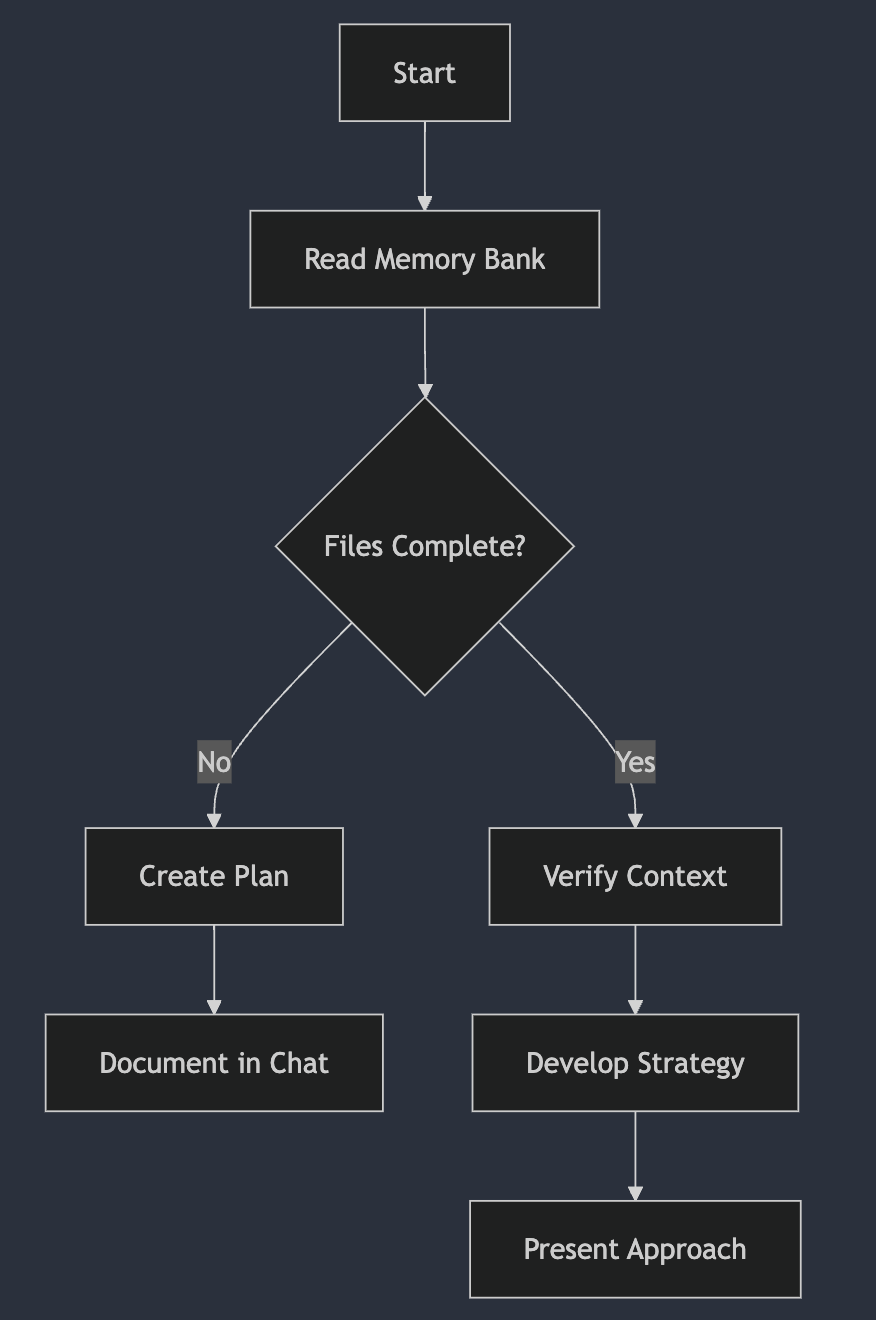
在 Memory Bank 中,Cline 提倡以 Mermaid 图表作为 Prompt,Cline 团队认为:
与 AI 交流的最佳方式并非自然语言——而是工作流的结构化语言。
Cline 的 Prompt 非常有模块化的设计思想。Cline 将 Prompt 划分为 System Prompt、Command、Workflow、Mention、Memery 等模块,System Prompt 则划分为工具、MCP、目标、Mode 等模块,针对全局、特定或者全新的任务使用不同的 Prompt 来解决。
同时我们也发现 Cline 事无巨细,非常“啰嗦”,比如 System Prompt 关于工具调用格式就出现了好几次;尽可能多的提供上下文,这让 Cline 非常的消耗 Token。
如何写出好用的 Prompt,个人感觉主要是两点:
- 足够的上下文和示例(身份、目标、工具、示例等等)
- 足够详细和明确的执行步骤(Workflow)
最后,可以查看官方文档提示词工程指南进一步了解如何为 Cline 写出更好用的 Prompt。
欢迎关注我的公众号:前端生存指南,一起聊聊前端、AI 和生活。